Introduction
mcmodule is a framework for building modular Monte Carlo
risk analysis models. It extends the capabilities of mc2d
to make working with multiple risk pathways, variates, and scenarios
easier. It was developed by epidemiologists, for the farmrisk project, and
now it aims to help epidemiologists and other risk modellers save time
and evaluate ambitious, complex risk pathways in R.
The mc2d R package (Pouillot and Delignette-Muller 2010)
provides tools to build and analyse models involving multiple variables
and uncertainties based on Monte Carlo simulations. The
mcmodule package includes additional tools to:
- Organize risk analysis in independent flexible modules
- Perform multivariate mcnode operations
- Automate the creation of mcnodes
- Visualise risk analysis models
- Perform model diagnosis such as convergence and sensitivity analysis
Multivariate Monte-Carlo simulations
Quantitative risk analysis is the numerical assessment of risk to facilitate decision making in the face of uncertainty. Monte Carlo simulation is a technique used to model and analyse uncertainty (Vose 2008).
In mc2d, parameters are stored as
mcnode class objects. These objects are arrays of
numbers that represent random variables and have three dimensions:
variability × uncertainty × variates. For more
information, see the mc2d package
vignette.
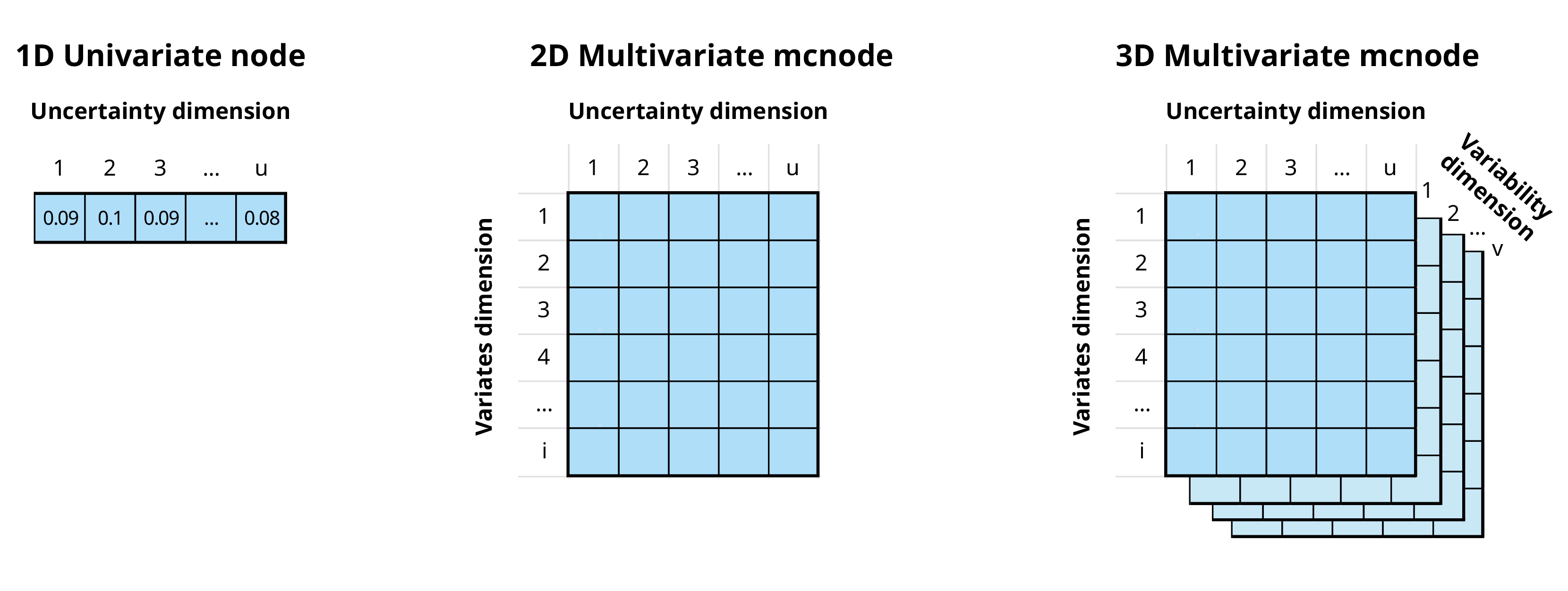
In the mcmodule framework an mcnode is an array of
dimensions (u × 1 × i):
We combine variability and uncertainty into one dimension1 (u)
We use variates (representing different groups or categories) in the other dimension (i)
The variables that define and distinguish these variates are called keys and are stored as metadata
In this document we will use the term “uncertainty dimension” to refer to the combined dimension of variability and uncertainty.
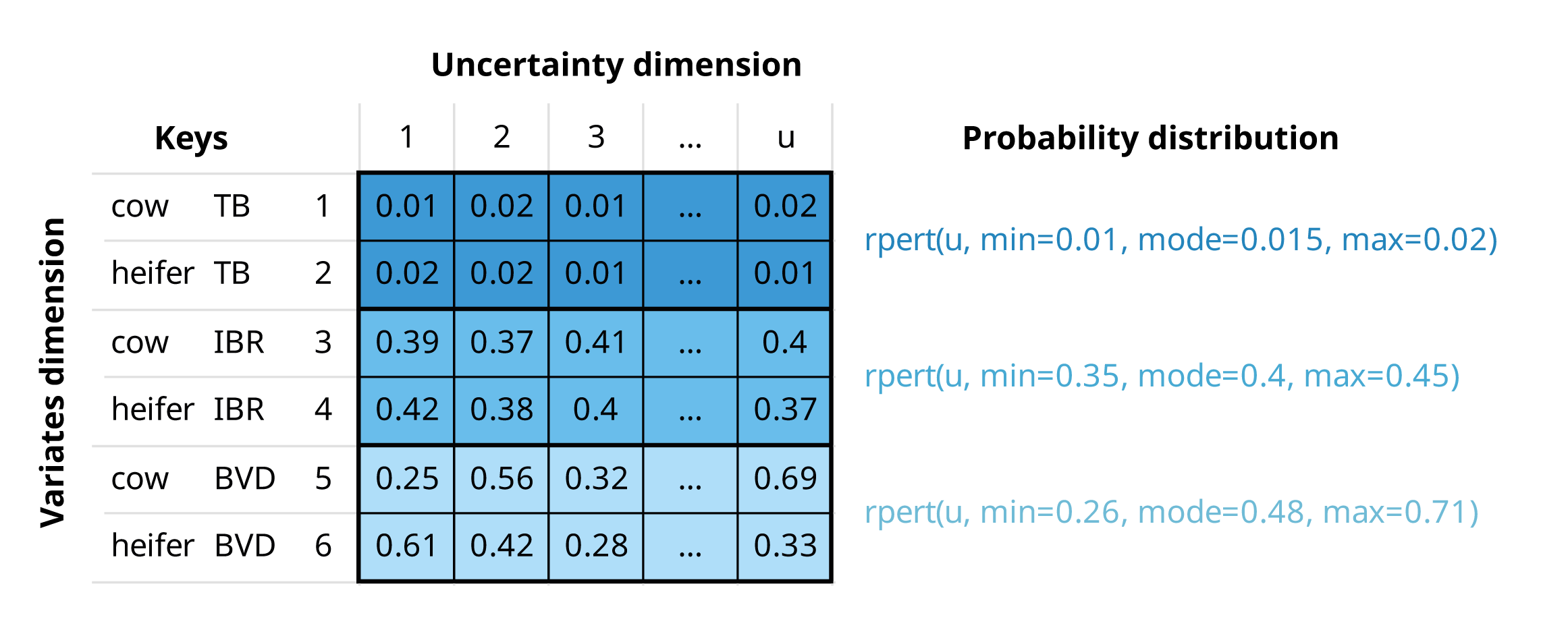
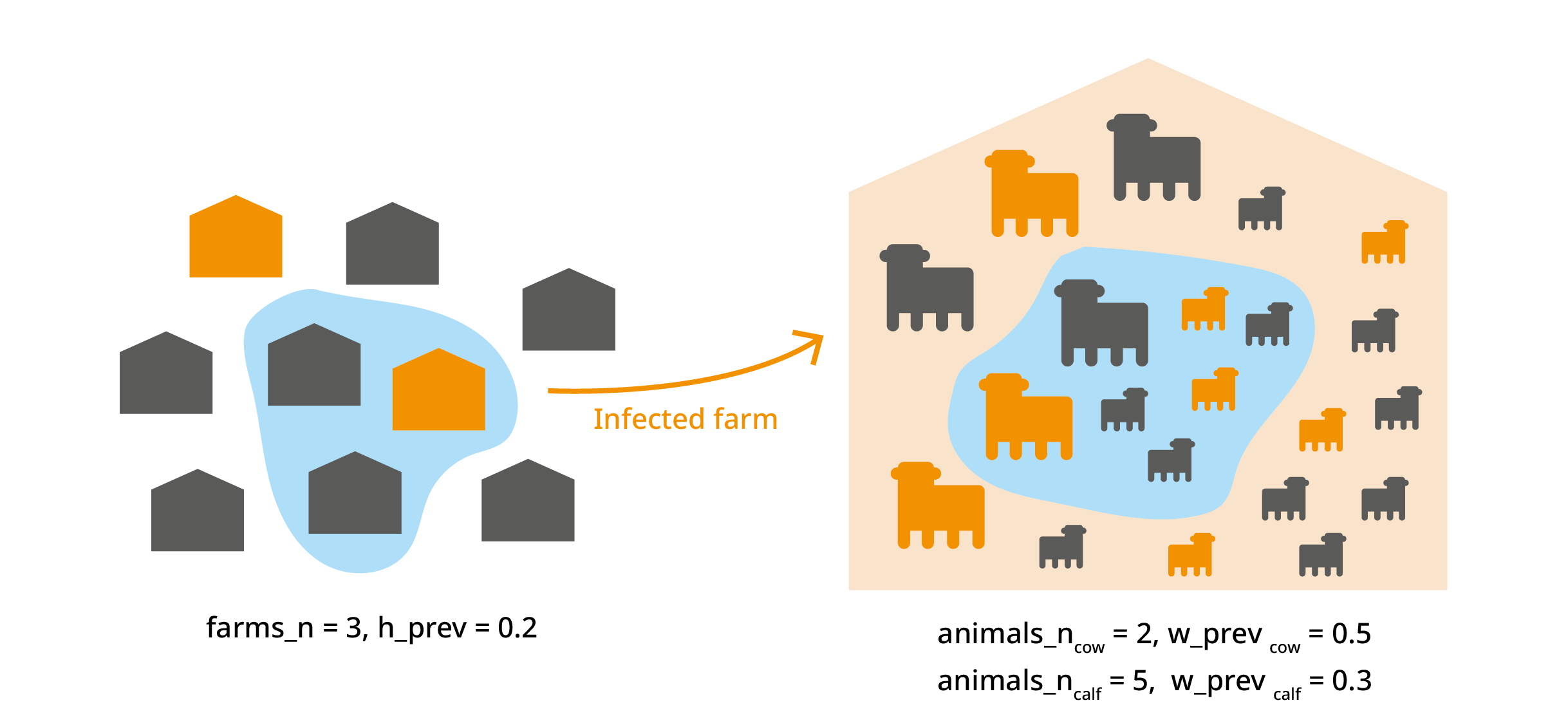
Example
If we are buying a number of cows and heifers from a specific region, an mcnode for herd prevalence would have:
Multiple variates (rows), defined by two keys: “animal category” and “pathogen”
Probability values generated through a PERT distribution, using minimum, mode, and maximum parameters across u iterations (columns) to model the uncertainty in these estimates
An mcnode representing herd prevalence of three pathogens, tuberculosis (TB), infectious bovine rhinotracheitis (IBR), and bovine viral diarrhoea (BVD), and two animal categories (cows and heifers). The herd prevalence is the same for both animal categories, but values differ due to the stochastic nature of random sampling from the PERT distribution.
Risk assessment
This section provides a brief introduction to risk assessment in R.
Although this package is not intended for beginners in risk assessment,
it can help you understand the logic behind mcmodule and
its purpose.
A simple risk assessment
Consider a scenario where we need to purchase a cow from a farm that we know is infected with a disease our farm is free from. To reduce the risk of introducing the disease to our farm, we plan to perform a diagnostic test on the cow before bringing it to our farm. We want to calculate the probability of introducing the disease by purchasing one cow that tests negative.
We have an estimation (with some uncertainty) of both the probability of animal infection within a herd and the test sensitivity, so we want to conduct a stochastic risk assessment that properly accounts for this uncertainty.
The risk assessment for our cattle purchase can be performed using
base R (2024)
random sampling functions, or mc2d (Pouillot and Delignette-Muller
2010), a package provides additional probability
distributions (such as rpert) and other useful tools for
analysing stochastic (Monte-Carlo) simulations.
library(mc2d)
set.seed(123)
n_iterations <- 10000
# Within-herd prevalence
w_prev <- mcstoc(runif,
min = 0.15, max = 0.2,
nsu = n_iterations, type = "U"
)
# Test sensitivity
test_sensi <- mcstoc(rpert,
min = 0.89, mode = 0.9, max = 0.91,
nsu = n_iterations, type = "U"
)
# Probability an animal is tested in origin
test_origin <- mcdata(1, type = "0") # Yes
# EXPRESSIONS
# Probability that an animal in an infected herd is infected (a = animal)
infected <- w_prev
# Probability an animal is tested and is a false negative
# (test specificity assumed to be 100%)
false_neg <- infected * test_origin * (1 - test_sensi)
# Probability an animal is not tested
no_test <- infected * (1 - test_origin)
# Probability an animal is not detected
no_detect <- false_neg + no_test
mc_model <- mc(
w_prev, infected, test_origin, test_sensi,
false_neg, no_test, no_detect
)
# RESULT
hist(mc_model)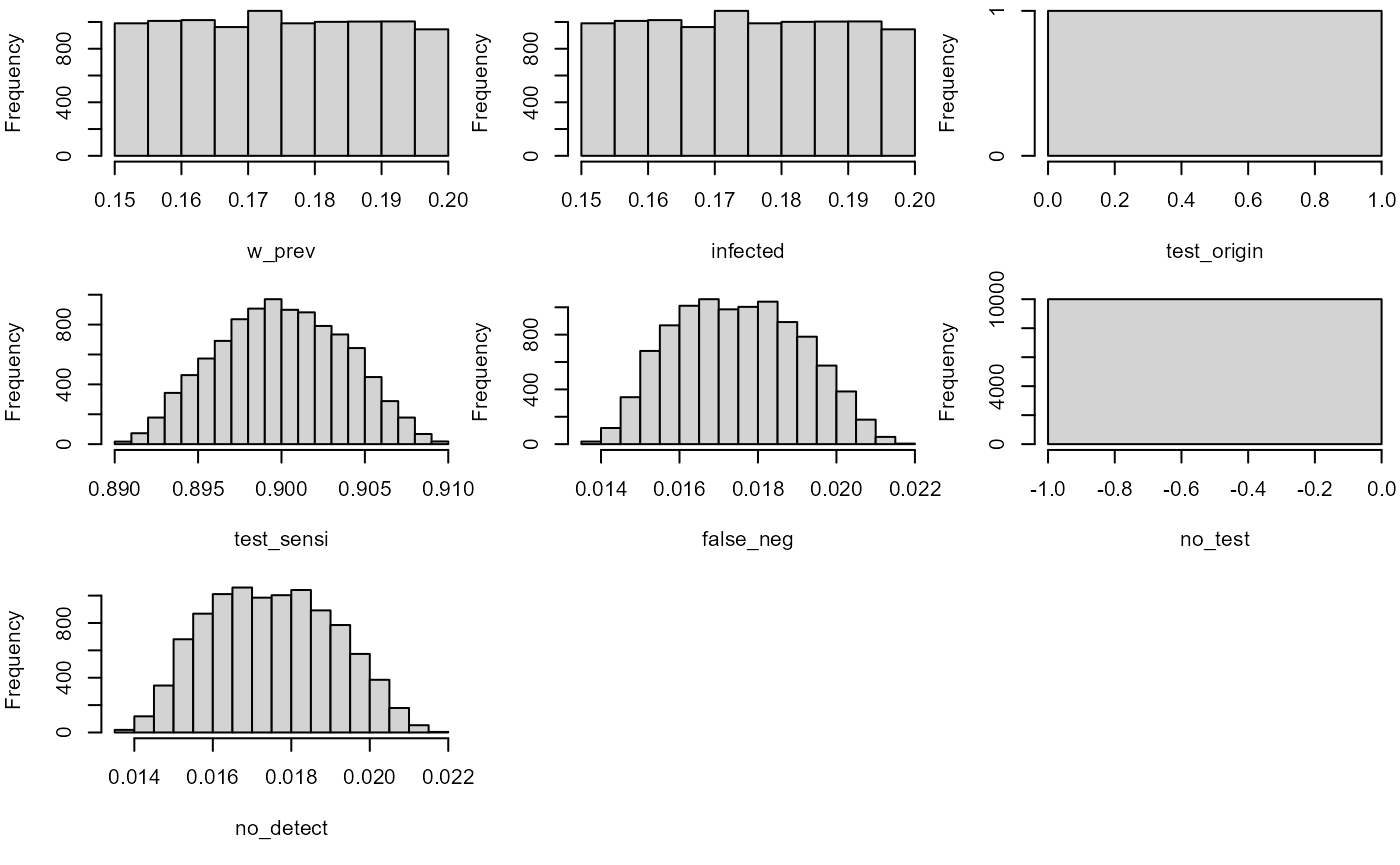
no_detect
#> node mode nsv nsu nva variate min mean median max Nas type outm
#> 1 x numeric 1 10000 1 1 0.0138 0.0175 0.0174 0.0218 0 U eachMultiple risk assessments at once
In the previous example, we calculated the risk for one specific case. However, we know that this farm is also positive for pathogen B, so it would be also interesting to calculate the risk of introducing it as well. Pathogen B has different within-herd prevalence and test sensitivity than Pathogen A.
To estimate the risk for both pathogens with our previous models, we could:
Copy and paste the code twice with different parameters (against all good coding practices)
Wrap the code in a function and call it twice using each pathogen’s parameters as arguments
Create a loop
While these options work, they become messy or computationally intensive when the number of parameters or different situations to simulate increases.
The package mc2d offers a clever solution to this
scalability problem: variates. In the previous example, our stochastic
nodes only had uncertainty dimension. However, we can now use the
variates dimension to calculate the risk of
introduction of both pathogens at the same time.
set.seed(123)
n_iterations <- 10000
# Within-herd prevalence
w_prev_min <- mcdata(c(a = 0.15, b = 0.45), nvariates = 2, type = "0")
w_prev_max <- mcdata(c(a = 0.2, b = 0.6), nvariates = 2, type = "0")
w_prev <- mcstoc(runif,
min = w_prev_min, max = w_prev_max,
nsu = n_iterations, nvariates = 2, type = "U"
)
# Test sensitivity
test_sensi_min <- mcdata(c(a = 0.89, b = 0.80), nvariates = 2, type = "0")
test_sensi_mode <- mcdata(c(a = 0.9, b = 0.85), nvariates = 2, type = "0")
test_sensi_max <- mcdata(c(a = 0.91, b = 0.90), nvariates = 2, type = "0")
test_sensi <- mcstoc(rpert,
min = test_sensi_min,
mode = test_sensi_mode, max = test_sensi_max,
nsu = n_iterations, nvariates = 2, type = "U"
)
# Probability an animal is tested in origin
test_origin <- mcdata(c(a = 1, b = 1), nvariates = 2, type = "0")
# EXPRESSIONS
# Probability that an animal in an infected herd is infected (a = animal)
infected <- w_prev
# Probability an animal is tested and is a false negative
# (test specificity assumed to be 100%)
false_neg <- infected * test_origin * (1 - test_sensi)
# Probability an animal is not tested
no_test <- infected * (1 - test_origin)
# Probability an animal is not detected
no_detect <- false_neg + no_test
mc_model <- mc(
w_prev, infected, test_origin, test_sensi,
false_neg, no_test, no_detect
)
# RESULT
no_detect
#> node mode nsv nsu nva variate min mean median max Nas type outm
#> 1 x numeric 1 10000 2 1 0.0139 0.0175 0.0174 0.0217 0 U each
#> 2 x numeric 1 10000 2 2 0.0477 0.0787 0.0783 0.1178 0 U eachWhen to use mcmodule?
The mc2d multivariate approach works well for basic
multivariate risk analysis. However, if instead of purchasing one cow,
you’re dealing with multiple cattle purchases, from different farms,
across different pathogens, scenarios, and age categories, or modelling
multiple risk pathways with different what-if scenarios, this approach
becomes unwieldy.
mcmodule addresses these challenges by providing
functions for multivariate operations and
modular management of the risk model. It automates the
process of creating mcnodes and assigns metadata to them (making it easy
to identify which variate corresponds to which data row). Thanks to this
mcnode metadata, it enables row-matching between nodes with different
variates, combines probabilities across variates, and calculates
multilevel trials. As your risk analysis grows, you can create separate
modules for different pathways, each with independent parameters,
expressions, and scenarios that can later be connected into a complete
model.
This package is particularly useful for:
Working with complex models that involve multiple pathways, pathogens, or scenarios simultaneously
Dealing with large parameter sets (hundreds or thousands of parameters)
Handling different numbers of variates across different parts of your model that need to be combined
Creating modular risk assessments where different components need to be developed independently but later integrated (for example in collaborative projects)
Performing sophisticated sensitivity analyses across multiple model components
However, for simpler analyses, such as single pathway models,
exploratory work, small models with few parameters, one-off analyses or
learning risk assessment mcmodule’s additional structure
may be unnecessary.
Installing mcmodule
Now, let’s explore the package! We can install it from CRAN:
install.packages("mcmodule")
library("mcmodule")Or install latest development version from GitHub (requires
devtool package):
# install.packages("pak")
pak::pkg_install("NataliaCiria/mcmodule")
library("mcmodule")Other recommended packages to load along with mcmodule are:
Building an mcmodule
To quickly understand the key components of an mcmodule, we’ll start by building one using the animal imports example included in the package.
Data
Let’s consider a scenario where we want to evaluate the risk of introducing pathogen A and pathogen B into our region from animal imports from different regions (north, south, east, and west). We have gathered the following data:
-
animal_imports: number of animal imports with their mean and standard deviation values per region, and the number of exporting farms in each region.animal_imports #> origin farms_n animals_n_mean animals_n_sd #> 1 nord 5 100 6 #> 2 south 10 130 10 #> 3 east 7 140 12 -
prevalence_region: estimates for both herd and within-herd prevalence ranges for pathogens A and B, as well as an indicator of how often tests are performed in originprevalence_region #> pathogen origin h_prev_min h_prev_max w_prev_min w_prev_max test_origin #> 1 a nord 0.08 0.10 0.15 0.2 sometimes #> 2 a south 0.02 0.05 0.15 0.2 sometimes #> 3 a east 0.10 0.15 0.15 0.2 never #> 4 b nord 0.50 0.70 0.45 0.6 always #> 5 b south 0.25 0.30 0.37 0.4 sometimes #> 6 b east 0.30 0.50 0.45 0.6 unknown -
test_sensitivity: estimates of test sensitivity values for pathogen A and Btest_sensitivity #> pathogen test_sensi_min test_sensi_mode test_sensi_max #> 1 a 0.89 0.90 0.91 #> 2 b 0.80 0.85 0.90
Now we will use dplyr::left_join() to create our imports
module data:
Data keys
From now on we will use only the merged imports_data
table. However, it is useful to understand which input dataset each
parameter comes from, as each dataset provides information for different
keys. In this context, keys are fields that (combined) uniquely identify
each row in a table. In our example:
animal_importsprovided information by region of"origin"prevalence_regionprovided information by"pathogen"and region of"origin"test_sensitivityprovided information by"pathogen"only
The resulting merged table, imports_data, will therefore
have two keys: "pathogen" and "origin".
However, not all parameters will use both keys, for example,
"test_sensi" only has information by
"pathogen". Knowing the keys for each parameter is crucial
when performing multivariate operations, such as calculating
totals.
To make these relationships explicit in the model, we need to provide the data keys. These are defined in a list with one element for each input dataset, specifying both the columns and the keys for each dataset.
mcnodes table
With values and keys established, we still need some information to build our stochastic parameters. The mcnode table specifies how to build mcnodes from the data table. It specifies which parameters are included in the model, the type of parameters (those with an mc_func are stochastic), and what columns to look for in the data table to build these mcnodes (the name of the mcnode, or another variable in the data columns), as well as transformations that are useful to encode categorical data values into mcnodes that must always be numeric.
mcnode: Name of the Monte Carlo node (required)
description: Description of the parameter
mc_func: Probability distribution
from_variable: Column name, if it comes from a column with a name different to the mcnode
sample_space: Sampling domain used by
sample_design()(for examplec(0, 1)ormin = 0, max = 1)transformation: Transformation to be applied to the original column values
sensi_variation: OAT variation expression using
valueplaceholder2
Here we have the imports_mctable for our example. While
the mctable can be hard-coded in R, it’s more efficient to prepare it in
a CSV or other external file. This approach also allows the table to be
included as part of the model documentation.
| mcnode | description | mc_func | from_variable | transformation | sensi_variation | sample_space |
|---|---|---|---|---|---|---|
| h_prev | Herd prevalence | runif | NA | NA | pmin(1, pmax(0, value * 1.5)) | min = 0.02, max = 0.7 |
| w_prev | Within herd prevalence | runif | NA | NA | pmin(1, pmax(0, value * 1.5)) | min = 0.15, max = 0.6 |
| test_sensi | Test sensitivity | rpert | NA | NA | pmin(1, pmax(0, value * 1.5)) | min = 0.8, mode = 0.875, max = 0.91 |
| farms_n | Number of farms exporting animals | NA | NA | NA | value * 1.5 | min = 5, max = 10 |
| animals_n | Number of animals exported per farm | rnorm | NA | NA | value * 1.5 | min = 82, max = 176 |
| test_origin_unk | Unknown probability of the animals being tested in origin (true = unknown) | NA | test_origin | value==“unknown” | ifelse(value == “unknown”, “always”, value) | NA |
| test_origin | Probability of the animals being tested in origin | NA | NA | ifelse(value == “always”, 1, ifelse(value == “sometimes”, 0.5, ifelse(value == “never”, 0, NA))) | pmin(1, pmax(0, value * 1.5)) | min = 0, max = 1 |
The data table and the mctable must complement each other:
mcnodes without an
mc_func(likefarms_n), needs the matching column name ("farms_n") in the data table-
mcnodes with an
mc_func, you need columns for each probability distribution argument in the data table. For example:h_prevwithrunifdistribution requires"h_prev_min"and"h_prev_max"animals_nwithrnormdistribution requires"animals_n_mean"and"animals_n_sd"
For encoding categorical variables as mcnodes (or any other data
transformation), you can use any R code with value as a
placeholder for the mcnode name or column name (specified in
from_variable)
Expressions
Finally, we need to write the model’s mathematical expression. These
expressions should ideally include only arithmetic operations, not R
functions (with some exceptions that will be covered later in “tricks
and tweaks”). We’ll wrap them using quote() so they
aren’t executed immediately but stored for later evaluation with
eval_model().
imports_exp <- quote({
# Probability that an animal in an infected herd is infected (a = animal)
infected <- w_prev
# Probability an animal is tested and is a false negative
# (test specificity assumed to be 100%)
false_neg <- infected * test_origin * (1 - test_sensi)
# Probability an animal is not tested
no_test <- infected * (1 - test_origin)
# Probability an animal is not detected
no_detect <- false_neg + no_test
})Creating mcnodes within expressions
Starting with version 1.2.0, you can create mcnodes directly inside
expressions using mcstoc() or mcdata() from
the mc2d package. However, these functions do not behave
exactly as they do in mc2d when used within
mcmodule. Keep the following points in mind:
- Do not set
nvariates. It is automatically set to match the number of rows in your data. - Use
type = "V"(variability, the default) ortype = "0"(deterministic). - All other
mcstoc()andmcdata()arguments behave as documented inmc2d.
# Example expression with mcnodes created on-the-fly
imports_exp_inline <- quote({
# Probability that an animal in an infected herd is infected
infected <- w_prev
# Create a clinic sensitivity parameter directly in the expression
# (no need to specify nvariates, it's inferred from data rows)
clinic_sensi <- mcstoc(runif, min = 0.6, max = 0.8)
# Probability an animal is tested and is a false negative
# Now accounting for both test sensitivity and clinic sensitivity
false_neg <- infected * test_origin * (1 - test_sensi) * (1 - clinic_sensi)
# Probability an animal is not tested but detected at clinic
no_test <- infected * (1 - test_origin) * (1 - clinic_sensi)
# Probability an animal is not detected
no_detect <- false_neg + no_test
})Evaluating an mcmodule
With all components in place, we’re now ready to create our first
mcmodule using eval_module().
imports <- eval_module(
exp = c(imports = imports_exp_inline),
data = imports_data,
mctable = imports_mctable,
data_keys = imports_data_keys
)
#> imports evaluated
#> mcmodule created (expressions: imports)
class(imports)
#> [1] "mcmodule"An mcmodule is an S3 object class, and it is essentially a list that contains all risk assessment components in a structured format.
names(imports)
#> [1] "data" "exp" "node_list"The mcmodule contains the input data and mathematical
expressions (exp) that ensure traceability. All input and
calculated parameters are stored in node_list. Each node
contains not only the mcnode itself but also important metadata: node
type (input or output), source dataset and columns, keys, calculation
method, and more. The specific metadata varies depending on the node’s
characteristics. Here are a few examples:
imports$node_list$w_prev
#> $type
#> [1] "in_node"
#>
#> $mc_func
#> [1] "runif"
#>
#> $description
#> [1] "Within herd prevalence"
#>
#> $inputs_col
#> [1] "w_prev_min" "w_prev_max"
#>
#> $input_dataset
#> [1] "prevalence_region"
#>
#> $keys
#> [1] "pathogen" "origin"
#>
#> $exp_name
#> [1] "imports"
#>
#> $mc_name
#> [1] "w_prev"
#>
#> $mcnode
#> node mode nsv nsu nva variate min mean median max Nas type outm
#> 1 x numeric 1001 1 6 1 0.15 0.175 0.175 0.2 0 V each
#> 2 x numeric 1001 1 6 2 0.15 0.175 0.173 0.2 0 V each
#> 3 x numeric 1001 1 6 3 0.15 0.176 0.176 0.2 0 V each
#> 4 x numeric 1001 1 6 4 0.45 0.524 0.524 0.6 0 V each
#> 5 x numeric 1001 1 6 5 0.37 0.385 0.385 0.4 0 V each
#> 6 x numeric 1001 1 6 6 0.45 0.525 0.525 0.6 0 V each
#>
#> $data_name
#> [1] "imports_data"
imports$node_list$no_detect
#> $function_call
#> [1] TRUE
#>
#> $type
#> [1] "out_node"
#>
#> $node_exp
#> [1] "false_neg + no_test"
#>
#> $inputs
#> [1] "false_neg" "no_test"
#>
#> $exp_name
#> [1] "imports"
#>
#> $mc_name
#> [1] "no_detect"
#>
#> $keys
#> [1] "pathogen" "origin"
#>
#> $exp_param
#> [1] "false_neg" "no_test"
#>
#> $mcnode
#> node mode nsv nsu nva variate min mean median max Nas type outm
#> 1 x numeric 1001 1 6 1 0.0169 0.0288 0.0286 0.0435 0 V each
#> 2 x numeric 1001 1 6 2 0.0173 0.0288 0.0288 0.0433 0 V each
#> 3 x numeric 1001 1 6 3 0.0305 0.0522 0.0519 0.0795 0 V each
#> 4 x numeric 1001 1 6 4 0.0113 0.0237 0.0231 0.0415 0 V each
#> 5 x numeric 1001 1 6 5 0.0427 0.0665 0.0659 0.0936 0 V each
#> 6 x numeric 1001 1 6 6 0.0910 0.1566 0.1550 0.2357 0 V each
#>
#> $data_name
#> [1] "imports_data"And now that we have an mcmodule, we can begin exploring its possibilities!

Working with an mcmodule
Visualizing
We can visualise an mc_module with the mc_network()
function. For this, you will need to have igraph (Csardi and Nepusz
2006) and visNetwork (Almende B. V. and Benoit Thieurmel
2025) installed.
In these network visualizations, input datasets appear in blue, input data files, input columns and input mcnodes appear in different shades of dark-grey-blue, output mcnodes in green, and total mcnodes (as we will see later) in orange. The numbers displayed when clicked correspond to the median and the 95% confidence interval of the first variate of each mcnode.
mc_network(imports, legend = TRUE)Summarizing
In the imports mcmodule, we can already see the raw mcnode results
for the probability of an imported animal not being detected
(no_detect). However, it’s difficult to determine which
pathogen or region these results refer to. The mc_summary()
function solves this problem by linking mcnode results with their key
columns in the data.
Note that while the printed summary looks similar to the raw mcnode, it’s actually just a dataframe containing statistical measures, whereas the actual mcnode is a large array of numbers with dimensions (uncertainty × 1 × variates),
mc_summary(mcmodule = imports, mc_name = "no_detect")
#> mc_name pathogen origin mean sd Min 2.5%
#> 1 no_detect a nord 0.02876295 0.005883480 0.01687456 0.01875305
#> 2 no_detect a south 0.02876181 0.005994587 0.01726271 0.01870397
#> 3 no_detect a east 0.05221667 0.011010899 0.03050241 0.03392336
#> 4 no_detect b nord 0.02368331 0.005669560 0.01132022 0.01435750
#> 5 no_detect b south 0.06651522 0.012734194 0.04266336 0.04540683
#> 6 no_detect b east 0.15664447 0.033952337 0.09097242 0.09980820
#> 25% 50% 75% 97.5% Max nsv Na's
#> 1 0.02387016 0.02863349 0.03333063 0.03959466 0.04351491 1001 0
#> 2 0.02375014 0.02877089 0.03307491 0.04063392 0.04326582 1001 0
#> 3 0.04312578 0.05186702 0.06064605 0.07355557 0.07948500 1001 0
#> 4 0.01930997 0.02309890 0.02751195 0.03579437 0.04150531 1001 0
#> 5 0.05585011 0.06591137 0.07797919 0.08748444 0.09355962 1001 0
#> 6 0.12933887 0.15496802 0.18097518 0.22205690 0.23574153 1001 0Filtering
Sometimes you may want to focus your analysis on specific subsets of
your data, such as a particular pathogen or region. The
mc_filter() function allows you to filter mcnodes based on
conditions, similar to dplyr::filter().
Filtering a single condition
Let’s filter the no_detect node to only include results
for pathogen “a”:
# Filter for pathogen a only
imports <- mc_filter(
imports,
"no_detect",
pathogen == "a",
name = "no_detect_pathogen_a"
)
# View the filtered results
imports$node_list$no_detect_pathogen_a$summary
#> mc_name pathogen origin mean sd
#> 1 no_detect_pathogen_a_filtered a nord 0.02876295 0.005883480
#> 2 no_detect_pathogen_a_filtered a south 0.02876181 0.005994587
#> 3 no_detect_pathogen_a_filtered a east 0.05221667 0.011010899
#> Min 2.5% 25% 50% 75% 97.5% Max
#> 1 0.01687456 0.01875305 0.02387016 0.02863349 0.03333063 0.03959466 0.04351491
#> 2 0.01726271 0.01870397 0.02375014 0.02877089 0.03307491 0.04063392 0.04326582
#> 3 0.03050241 0.03392336 0.04312578 0.05186702 0.06064605 0.07355557 0.07948500
#> nsv Na's
#> 1 1001 0
#> 2 1001 0
#> 3 1001 0Filtering with multiple conditions
You can also apply multiple filter conditions at once. For example, to analyze only pathogen “b” from the “nord” region:
# Filter for pathogen b from nord region
imports <- mc_filter(
imports,
"no_detect",
pathogen == "b",
origin == "nord",
name = "no_detect_b_nord"
)
# View the filtered results
imports$node_list$no_detect_b_nord$summary
#> mc_name pathogen origin mean sd Min
#> 4 no_detect_b_nord_filtered b nord 0.02368331 0.00566956 0.01132022
#> 2.5% 25% 50% 75% 97.5% Max nsv Na's
#> 4 0.0143575 0.01930997 0.0230989 0.02751195 0.03579437 0.04150531 1001 0The filtered nodes maintain all the metadata from the original node and can be used in subsequent calculations just like any other node in the mcmodule.
Calculating totals
Most of the following probability calculations are based on Chapter 5 of the Handbook on Import Risk Analysis for Animals and Animal Products Volume 2. Quantitative risk assessment (Murray 2004). More details can be found on the Multivariate operations vignette.
Single-level trials
In imports, we know the probability that an infected
animal from an infected farm goes undetected ("no_detect").
We can use the total number of animals selected per farm
("animals_n") as the number of trials
(trials_n) to determine the probability that at least one
infected animal from an infected farm is not detected
(no_detect_set).
In single-level trials, each trial is independent with the same probability of success (). For a set of trials, the probability of at least one success is:
# Probability of at least one imported animal from an infected herd is not detected
imports <- trial_totals(
mcmodule = imports,
mc_names = "no_detect",
trials_n = "animals_n",
mctable = imports_mctable
)The trial_totals() function returns the mcmodule with
some additional nodes: the probability of at least one success and the
expected number of successes. These total nodes have
special metadata fields, and always include a summary by default.
# Probability of at least one
imports$node_list$no_detect_set$summary
#> mc_name pathogen origin mean sd Min 2.5%
#> 1 no_detect_set a nord 0.9353649 3.883557e-02 0.7861311 0.8430134
#> 2 no_detect_set a south 0.9688685 2.434001e-02 0.8521708 0.9053670
#> 3 no_detect_set a east 0.9982705 2.713104e-03 0.9779484 0.9896240
#> 4 no_detect_set b nord 0.8925258 5.809912e-02 0.6801729 0.7620536
#> 5 no_detect_set b south 0.9994921 8.394029e-04 0.9937705 0.9971897
#> 6 no_detect_set b east 0.9999999 1.007295e-06 0.9999716 0.9999996
#> 25% 50% 75% 97.5% Max nsv Na's
#> 1 0.9110563 0.9449214 0.9664750 0.9839338 0.9903200 1001 0
#> 2 0.9556170 0.9767071 0.9875921 0.9960537 0.9987422 1001 0
#> 3 0.9978473 0.9994127 0.9998526 0.9999866 0.9999976 1001 0
#> 4 0.8568207 0.9028213 0.9383441 0.9732375 0.9913663 1001 0
#> 5 0.9993476 0.9998565 0.9999701 0.9999948 0.9999994 1001 0
#> 6 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000 1001 0
# Expected number of animals
imports$node_list$no_detect_set_n$summary
#> mc_name pathogen origin mean sd Min 2.5%
#> 1 no_detect_set_n a nord 2.881746 0.6124382 1.529033 1.833821
#> 2 no_detect_set_n a south 3.740006 0.8357107 1.894541 2.335889
#> 3 no_detect_set_n a east 7.330762 1.6711952 3.754963 4.480383
#> 4 no_detect_set_n b nord 2.361640 0.5839372 1.132675 1.423825
#> 5 no_detect_set_n b south 8.613970 1.7498539 4.958773 5.733913
#> 6 no_detect_set_n b east 22.012662 5.1394951 9.971617 13.895154
#> 25% 50% 75% 97.5% Max nsv Na's
#> 1 2.391553 2.857134 3.339671 4.051653 4.536046 1001 0
#> 2 3.079032 3.707894 4.320097 5.424437 6.535555 1001 0
#> 3 6.003530 7.242773 8.544794 10.827406 12.409943 1001 0
#> 4 1.923674 2.303978 2.749540 3.555514 4.654709 1001 0
#> 5 7.123986 8.552104 10.002242 11.658403 13.687274 1001 0
#> 6 18.048291 21.529684 25.817968 32.375069 36.016324 1001 0Multilevel trials
Simple multilevel
We can also calculate the probability that at least one infected animal from at least one infected farm is not detected, but here, we need to consider two levels: animals and farms.
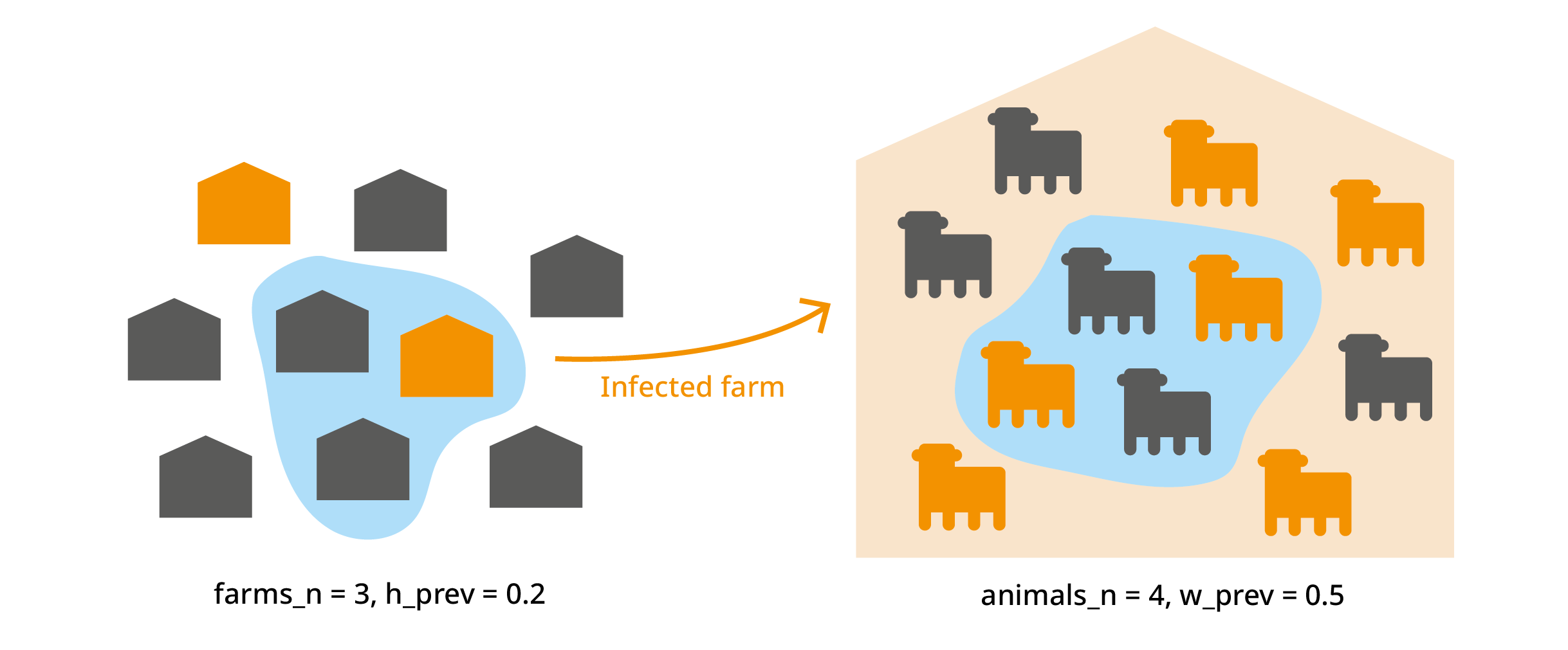
We import animals from "farms_n" farms. Each farm has a
probability "h_prev" (regional herd prevalence) of being
infected. From each farm, we import "animals_n" animals. In
an infected farm, each animal has a probability "w_prev"
(within-herd prevalence) of being infected. We’ve already used this to
calculate "no_detect", which is the probability that an
infected animal is not detected.

The probability of at least one success in this hierarchical structure is given by:
Where:
trials_p represents the probability of a trial in a subset being a success
trials_n represents the number of trials in subset
subset_p represents the probability of a subset being selected
subset_n represents the number of subsets
set_p represents the probability of a at least one trial of at least one subset being a success
# Probability of at least one animal from at least one herd being is not detected (probability of a herd being infected: h_prev)
imports <- trial_totals(
mcmodule = imports,
mc_names = "no_detect",
trials_n = "animals_n",
subsets_n = "farms_n",
subsets_p = "h_prev",
mctable = imports_mctable,
)
# Result
imports$node_list$no_detect_set$summary
#> mc_name pathogen origin mean sd Min 2.5%
#> 1 no_detect_set a nord 0.3554524 0.022994131 0.2879914 0.3121972
#> 2 no_detect_set a south 0.2918725 0.062035936 0.1707131 0.1841581
#> 3 no_detect_set a east 0.6031702 0.044184854 0.5206358 0.5262034
#> 4 no_detect_set b nord 0.9746355 0.016235524 0.9080894 0.9353931
#> 5 no_detect_set b south 0.9593916 0.008324214 0.9435923 0.9445593
#> 6 no_detect_set b east 0.9662035 0.021220418 0.9176483 0.9211130
#> 25% 50% 75% 97.5% Max nsv Na's
#> 1 0.3379731 0.3553841 0.3732035 0.3966264 0.4037282 1001 0
#> 2 0.2363502 0.2957188 0.3458267 0.3884192 0.3984394 1001 0
#> 3 0.5662145 0.6055760 0.6393578 0.6753059 0.6787207 1001 0
#> 4 0.9653477 0.9783262 0.9873528 0.9947945 0.9963197 1001 0
#> 5 0.9523539 0.9602221 0.9666917 0.9714390 0.9717183 1001 0
#> 6 0.9508097 0.9717442 0.9848915 0.9915584 0.9921264 1001 0It also provides the probability of at least one and the expected number of infected animals by subset (in this case a farm)
# Probability of at least one in a farm
imports$node_list$no_detect_subset$summary
#> mc_name pathogen origin mean sd Min 2.5%
#> 1 no_detect_subset a nord 0.08418689 0.006531174 0.06567697 0.07211792
#> 2 no_detect_subset a south 0.03425691 0.008450613 0.01854480 0.02014774
#> 3 no_detect_subset a east 0.12435837 0.013995100 0.09971337 0.10121463
#> 4 no_detect_subset b nord 0.53616683 0.061836633 0.37959809 0.42182969
#> 5 no_detect_subset b south 0.27549957 0.014904524 0.24987461 0.25117068
#> 6 no_detect_subset b east 0.39950577 0.057881309 0.30000310 0.30428818
#> 25% 50% 75% 97.5% Max nsv Na's
#> 1 0.0791792 0.08407440 0.0891952 0.09610651 0.09824438 1001 0
#> 2 0.0266043 0.03445036 0.0415504 0.04798151 0.04955292 1001 0
#> 3 0.1124718 0.12445096 0.1355792 0.14844909 0.14973428 1001 0
#> 4 0.4895580 0.53528475 0.5827474 0.65062396 0.67403048 1001 0
#> 5 0.2624308 0.27562373 0.2883684 0.29922709 0.29991533 1001 0
#> 6 0.3496821 0.39920048 0.4505998 0.49443719 0.49944352 1001 0Multiple group multilevel trials
This trial_totals() application is beyond the scope of
this vignette, but there are cases where you might have several variates
from the same subset. For example we could deal with different animal
categories (cow, calf, bull…) from the same farm. In this case, the
infection probability of animals within the same farm is not
independent, and this should be taken into account. For more
information, see Multilevel
trials in the Multivariate operations vignette.
Aggregated totals
Until this point, all mcnode operations were element-wise, keeping
the original dimensions, and allowing uncertainties and variates to
propagate through the calculations. However, sometimes, we need to
aggregate variates to calculate totals, for example, to total risk of
introducing a pathogen across all regions. In this case, we want to
preserve the uncertainty dimension but reduce the variates dimension.
With agg_totals() we can calculate overall probabilities or
sum quantities across groups.
imports <- agg_totals(
mcmodule = imports,
mc_name = "no_detect_set",
agg_keys = "pathogen"
)
#> 3 variates per group for no_detect_set
# Result
imports$node_list$no_detect_set_agg$summary
#> mc_name pathogen mean sd Min 2.5%
#> 1 no_detect_set_agg a 0.8188637 2.656678e-02 0.7330214 0.7635315
#> 4 no_detect_set_agg b 0.9999646 3.709019e-05 0.9996568 0.9998676
#> 25% 50% 75% 97.5% Max nsv Na's
#> 1 0.8005996 0.8199115 0.8383779 0.8657543 0.8790562 1001 0
#> 4 0.9999557 0.9999769 0.9999892 0.9999968 0.9999988 1001 0Now we can visualise our mcmodule again and see all these new nodes created by the totals functions.
mc_network(imports, legend = TRUE)Working with what-if scenarios
So far, we’ve only tested our model using current data. But risk analysis is most useful when comparing different scenarios. In our example, we could compare the baseline risk with the risk if tests were always performed in all regions.
To do this this, we only need to add a column called “scenario_id”. This name is important as it is used to will recognize it specifically for scenario comparisons, not as regular variate categories. The baseline scenario should be called “0”. While not every scenario needs to contain all the variate categories included in the baseline, any variate categories present in alternative scenarios must exist in the baseline.
imports_data <- imports_data %>%
mutate(scenario_id = "0")
imports_data_wif <- imports_data %>%
mutate(
scenario_id = "always_test",
test_origin = "always"
) %>%
bind_rows(imports_data) %>%
relocate(scenario_id)
imports_data_wif[, 1:6]
#> scenario_id pathogen origin test_origin h_prev_min h_prev_max
#> 1 always_test a nord always 0.08 0.10
#> 2 always_test a south always 0.02 0.05
#> 3 always_test a east always 0.10 0.15
#> 4 always_test b nord always 0.50 0.70
#> 5 always_test b south always 0.25 0.30
#> 6 always_test b east always 0.30 0.50
#> 7 0 a nord sometimes 0.08 0.10
#> 8 0 a south sometimes 0.02 0.05
#> 9 0 a east never 0.10 0.15
#> 10 0 b nord always 0.50 0.70
#> 11 0 b south sometimes 0.25 0.30
#> 12 0 b east unknown 0.30 0.50Now we create the mcmodule and calculate the totals. Note that, since
most functions for working with mcmodules both take and return
mcmodules, you can use the pipe %>% to simplify your
workflow
imports_wif <- eval_module(
exp = c(imports = imports_exp),
data = imports_data_wif,
mctable = imports_mctable,
data_keys = imports_data_keys
)
#> imports evaluated
#> mcmodule created (expressions: imports)
imports_wif <- imports_wif %>%
trial_totals(
mc_names = "no_detect",
trials_n = "animals_n",
subsets_n = "farms_n",
subsets_p = "h_prev",
mctable = imports_mctable,
) %>%
agg_totals(
mc_name = "no_detect_set",
agg_keys = c("pathogen", "scenario_id")
)
#> 3 variates per group for no_detect_set
# Result
imports_wif$node_list$no_detect_set_agg$summary
#> mc_name scenario_id pathogen mean sd Min
#> 1 no_detect_set_agg always_test a 0.7874198 2.858463e-02 0.6926341
#> 4 no_detect_set_agg always_test b 0.9999831 1.708178e-05 0.9998825
#> 7 no_detect_set_agg 0 a 0.8266259 2.563749e-02 0.7525038
#> 10 no_detect_set_agg 0 b 0.9999822 1.896049e-05 0.9998809
#> 2.5% 25% 50% 75% 97.5% Max nsv Na's
#> 1 0.7267729 0.7691942 0.7889077 0.8079228 0.8354961 0.8499450 1001 0
#> 4 0.9999376 0.9999776 0.9999892 0.9999945 0.9999985 0.9999992 1001 0
#> 7 0.7724774 0.8094927 0.8281388 0.8464569 0.8705576 0.8808379 1001 0
#> 10 0.9999266 0.9999768 0.9999894 0.9999947 0.9999985 0.9999993 1001 0Once scenario totals are available, we can directly compare each
what-if scenario against baseline using mc_compare(). Here
we compute the relative risk reduction in
no_detect_set_agg for each pathogen:
imports_wif <- mc_compare(
mcmodule = imports_wif,
mc_name = "no_detect_set_agg",
baseline = "0",
type = "relative_reduction",
name = "no_detect_set_rrr"
)
#> .temp_baseline_no_detect_set_agg prev dim: [1001, 1, 2], new dim: [1001, 1, 2], 0 null matches
#> .temp_whatif_no_detect_set_agg prev dim: [1001, 1, 2], new dim: [1001, 1, 2], 0 null matches
# Relative risk reduction by pathogen and scenario
imports_wif$node_list$no_detect_set_rrr_compared$summary
#> mc_name scenario_id pathogen mean sd
#> 1 no_detect_set_rrr_compared always_test a 4.75836e-02 5.794338e-03
#> 2 no_detect_set_rrr_compared always_test b -8.37004e-07 3.581123e-06
#> Min 2.5% 25% 50% 75%
#> 1 0.0252790495 3.808800e-02 4.468384e-02 4.695074e-02 4.932815e-02
#> 2 -0.0000248118 -1.238993e-05 -5.009596e-07 -3.139464e-08 3.097961e-07
#> 97.5% Max nsv Na's
#> 1 6.234739e-02 0.0795606388 1001 0
#> 2 1.250364e-06 0.0000341754 1001 0Working with multiple mcmodules
As your risk analysis grows in complexity, you may need to split your model into several independent modules and then combine them.
Inputs from previous mcmodules
Often, the output from one module serves as input for another. For example, after estimating the probability that an imported animal is not detected, you may want to model the probability that this animal transmits a pathogen via direct contact.
To do this, simply pass the previous mcmodule as the
prev_mcmodule argument when creating the new module. This
makes all nodes from the previous module available for use in
expressions in the new module.
# Create pathogen data table
transmission_data <- data.frame(
pathogen = c("a", "b"),
inf_dc_min = c(0.05, 0.3),
inf_dc_max = c(0.08, 0.4)
)
transmission_data_keys <- list(transmission_data = list(
cols = c("pathogen", "inf_dc_min", "inf_dc_max"),
keys = c("pathogen")
))
transmission_mctable <- data.frame(
mcnode = c("inf_dc"),
description = c("Probability of infection via direct contact"),
mc_func = c("runif")
)
dir_contact_exp <- quote({
dir_contact <- no_detect * inf_dc
})
transmission <- eval_module(
exp = c(dir_contact = dir_contact_exp),
data = transmission_data,
mctable = transmission_mctable,
data_keys = transmission_data_keys,
prev_mcmodule = imports_wif
)
#> Group by: pathogen
#> no_detect prev dim: [1001, 1, 12], new dim: [1001, 1, 12], 0 null matches
#> data prev dim: [2, 3], new dim: [12, 4], 0 null matches
#> dir_contact evaluated
#> mcmodule created (expressions: dir_contact)
mc_network(transmission, legend = TRUE)Combining mcmodules
To merge two or more modules into a single unified model, use the
combine_modules() function. This will join their data,
nodes, and expressions, allowing you to perform further calculations or
summaries across the combined structure.
intro <- combine_modules(imports_wif, transmission)
intro <- at_least_one(intro, c("no_detect", "dir_contact"), name = "total")
#> 2 variates per group for dir_contact
#> 2 variates per group for dir_contact
#> 2 variates per group for dir_contact
#> 2 variates per group for dir_contact
#> no_detect prev dim: [1001, 1, 12], new dim: [1001, 1, 24], 0 null matches
#> dir_contact prev dim: [1001, 1, 12], new dim: [1001, 1, 24], 0 null matches
intro$node_list$total$summary
#> mc_name scenario_id pathogen origin mean sd Min
#> 1 total always_test a nord 0.01860746 0.001694235 0.01505334
#> 2 total always_test a nord 0.02360539 0.001862613 0.01859826
#> 3 total always_test a south 0.01867471 0.001672139 0.01452327
#> 4 total always_test a south 0.02364453 0.001828060 0.01894177
#> 5 total always_test a east 0.01860590 0.001666259 0.01492699
#> 6 total always_test a east 0.02870885 0.002352851 0.02282254
#> 7 total always_test b nord 0.10487210 0.015719328 0.06511396
#> 8 total always_test b nord 0.10476421 0.012337670 0.07113198
#> 9 total always_test b south 0.07674767 0.009667128 0.05247253
#> 10 total always_test b south 0.13082810 0.009151394 0.10657070
#> 11 total always_test b east 0.10422042 0.015102873 0.06556958
#> 12 total always_test b east 0.24911716 0.023046499 0.18625081
#> 13 total 0 a nord 0.09727544 0.008136636 0.08301633
#> 14 total 0 a nord 0.10186819 0.008615486 0.08614423
#> 15 total 0 a south 0.09699393 0.007971058 0.08301089
#> 16 total 0 a south 0.10156323 0.008388948 0.08678525
#> 17 total 0 a east 0.17548509 0.014401197 0.15098265
#> 18 total 0 a east 0.18395965 0.015066092 0.15673076
#> 19 total 0 b nord 0.10426658 0.012470600 0.07159781
#> 20 total 0 b nord 0.10405505 0.015674473 0.06430465
#> 21 total 0 b south 0.23735849 0.006294698 0.21920964
#> 22 total 0 b south 0.28200208 0.008789215 0.26096689
#> 23 total 0 b east 0.53958631 0.042783172 0.46163966
#> 24 total 0 b east 0.61334456 0.044035157 0.52708971
#> 2.5% 25% 50% 75% 97.5% Max nsv Na's
#> 1 0.01559512 0.01724262 0.01853864 0.01995688 0.02162698 0.02309612 1001 0
#> 2 0.01999250 0.02228049 0.02363746 0.02487707 0.02719192 0.02847248 1001 0
#> 3 0.01567566 0.01742340 0.01861120 0.01996783 0.02175420 0.02298326 1001 0
#> 4 0.02025486 0.02238904 0.02357265 0.02501336 0.02713315 0.02923643 1001 0
#> 5 0.01570821 0.01722734 0.01858450 0.01990100 0.02181710 0.02274172 1001 0
#> 6 0.02437838 0.02712347 0.02873136 0.03031437 0.03350782 0.03570205 1001 0
#> 7 0.07663705 0.09318886 0.10443184 0.11728159 0.13475111 0.15089136 1001 0
#> 8 0.08191313 0.09591344 0.10461550 0.11345132 0.12835961 0.14381099 1001 0
#> 9 0.05892323 0.06963682 0.07667132 0.08361251 0.09540084 0.10161483 1001 0
#> 10 0.11349717 0.12427431 0.13082240 0.13709414 0.14921303 0.15859317 1001 0
#> 11 0.07550361 0.09381417 0.10330175 0.11484037 0.13416027 0.14854850 1001 0
#> 12 0.20577284 0.23305853 0.24862509 0.26522469 0.29325353 0.31490756 1001 0
#> 13 0.08417800 0.09021989 0.09686026 0.10470682 0.11030376 0.11180134 1001 0
#> 14 0.08804692 0.09432703 0.10124709 0.10955885 0.11579604 0.11742450 1001 0
#> 15 0.08427860 0.09003083 0.09685497 0.10354843 0.11055153 0.11165979 1001 0
#> 16 0.08788572 0.09443001 0.10158955 0.10839472 0.11590172 0.11773358 1001 0
#> 17 0.15224723 0.16285288 0.17555824 0.18813205 0.19977594 0.20098946 1001 0
#> 18 0.15975360 0.17087945 0.18384978 0.19751792 0.20931317 0.21240362 1001 0
#> 19 0.08025314 0.09553021 0.10392086 0.11251040 0.12997916 0.13834071 1001 0
#> 20 0.07469573 0.09258978 0.10412327 0.11391837 0.13566105 0.14994785 1001 0
#> 21 0.22564411 0.23297740 0.23718737 0.24216762 0.24909254 0.25667639 1001 0
#> 22 0.26641192 0.27568578 0.28169115 0.28819092 0.29860276 0.30576361 1001 0
#> 23 0.46891312 0.50295017 0.53938946 0.57707039 0.60817207 0.61312262 1001 0
#> 24 0.53811484 0.57543314 0.61434412 0.65127705 0.68513360 0.69490091 1001 0
mc_network(intro, legend = TRUE)The combined module now contains all nodes and metadata from its components, enabling you to analyze interactions and aggregate results across the entire risk pathway.
Getting module information
The mcmodule_info() function provides comprehensive
metadata about your mcmodule structure, including composition
information, keys for each variate, and global keys used across the
module.
mcmodule_info(intro)
#> $is_combined
#> [1] TRUE
#>
#> $n_modules
#> [1] 2
#>
#> $module_names
#> [1] "imports_wif" "transmission"
#>
#> $module_exp_data
#> module exp data_name
#> 1 imports_wif imports imports_data_wif
#> 2 transmission dir_contact transmission_data
#>
#> $data_keys
#> scenario_id pathogen origin variate data_name
#> 1 always_test a nord 1 imports_data_wif
#> 2 always_test a south 2 imports_data_wif
#> 3 always_test a east 3 imports_data_wif
#> 4 always_test b nord 4 imports_data_wif
#> 5 always_test b south 5 imports_data_wif
#> 6 always_test b east 6 imports_data_wif
#> 7 0 a nord 7 imports_data_wif
#> 8 0 a south 8 imports_data_wif
#> 9 0 a east 9 imports_data_wif
#> 10 0 b nord 10 imports_data_wif
#> 11 0 b south 11 imports_data_wif
#> 12 0 b east 12 imports_data_wif
#> 13 <NA> a nord 1 transmission_data
#> 14 <NA> a south 2 transmission_data
#> 15 <NA> a east 3 transmission_data
#> 16 <NA> b nord 4 transmission_data
#> 17 <NA> b south 5 transmission_data
#> 18 <NA> b east 6 transmission_data
#> 19 <NA> a nord 7 transmission_data
#> 20 <NA> a south 8 transmission_data
#> 21 <NA> a east 9 transmission_data
#> 22 <NA> b nord 10 transmission_data
#> 23 <NA> b south 11 transmission_data
#> 24 <NA> b east 12 transmission_data
#>
#> $global_keys
#> [1] "pathogen" "origin" "scenario_id"
#>
#> $node_counts
#> module n_nodes n_in_node n_out_node n_total n_agg_total n_compare
#> 1 imports_wif 8 3 5 0 0 0
#> 2 intro 11 3 0 6 1 1
#> 3 transmission 2 1 1 0 0 0Model analysis
Convergence analysis
The mcmodule_converg() function assesses whether your
Monte Carlo simulations have run for enough iterations to produce stable
results. It tracks how statistics (mean, median, quantiles) change as
iterations accumulate.
converg_results <- mcmodule_converg(imports)
#>
#> === Convergence Analysis Summary ===
#>
#> Analysis Parameters
#> - Number of simulations: 1001
#> - Total nodes analyzed: 17
#> - Total variates analyzed: 87
#> - Simulation quantile range: 0.95 to 1
#> - Simulations range: 950 to 1001 (51 simulations)
#>
#> Convergence Results
#> Maximum divergence of node summary statistics (mean, median, 2.5th percentile and 97.5th percentile):
#>
#> - More than 1% divergence: 0 (0%)
#>
#> - More than 2.5% divergence: 0 (0%)
#>
#> - More than 5% divergence: 0 (0%)
#>
#> All nodes successfully converged at 1%% threshold! :DCorrelation analysis
The mcmodule_corr() function calculates correlation
coefficients between input and output nodes across your mcmodule, and
mcmodule_tornado() creates a plot to visualize this
correlations. This helps identify which input parameters have the
strongest influence on your results. It is based on
mc2d::tornado() but can be applied to multivariate
inputs.
# Calculate correlations using Spearman's method (default)
mcmodule_tornado(imports)
#>
#> === Correlation Analysis Summary ===
#>
#> Analysis Parameters:
#> - Analysis type: Global output
#> - Output node: no_detect_set_agg
#> - Correlation method(s): spearman
#> - Missing value handling: all.obs
#>
#> Expression Information:
#> - Module: mcmodule
#> - Expression: imports
#> - Input nodes: w_prev, test_sensi, animals_n, h_prev
#> - Variates analyzed: 6
#>
#> Results Summary:
#> - Total correlations calculated: 24
#> - Top 4 most influential inputs (by absolute mean correlation):
#> 1. h_prev: 0.5044
#> 2. animals_n: 0.0457
#> 3. w_prev: 0.0399
#> 4. test_sensi: -0.0340
#>
#> Input Correlation Strength Distribution:
#> - Very strong: 0 (0.0%)
#> - Strong: 2 (8.3%)
#> - Moderate: 2 (8.3%)
#> - Weak: 1 (4.2%)
#> - Very weak/None: 19 (79.2%)
#>
#> Inputs by Correlation Strength:
#> - Strong: h_prev
#> - Moderate: h_prev
#> - Weak: h_prev
#> - Very weak/None: w_prev, test_sensi, animals_n, h_prev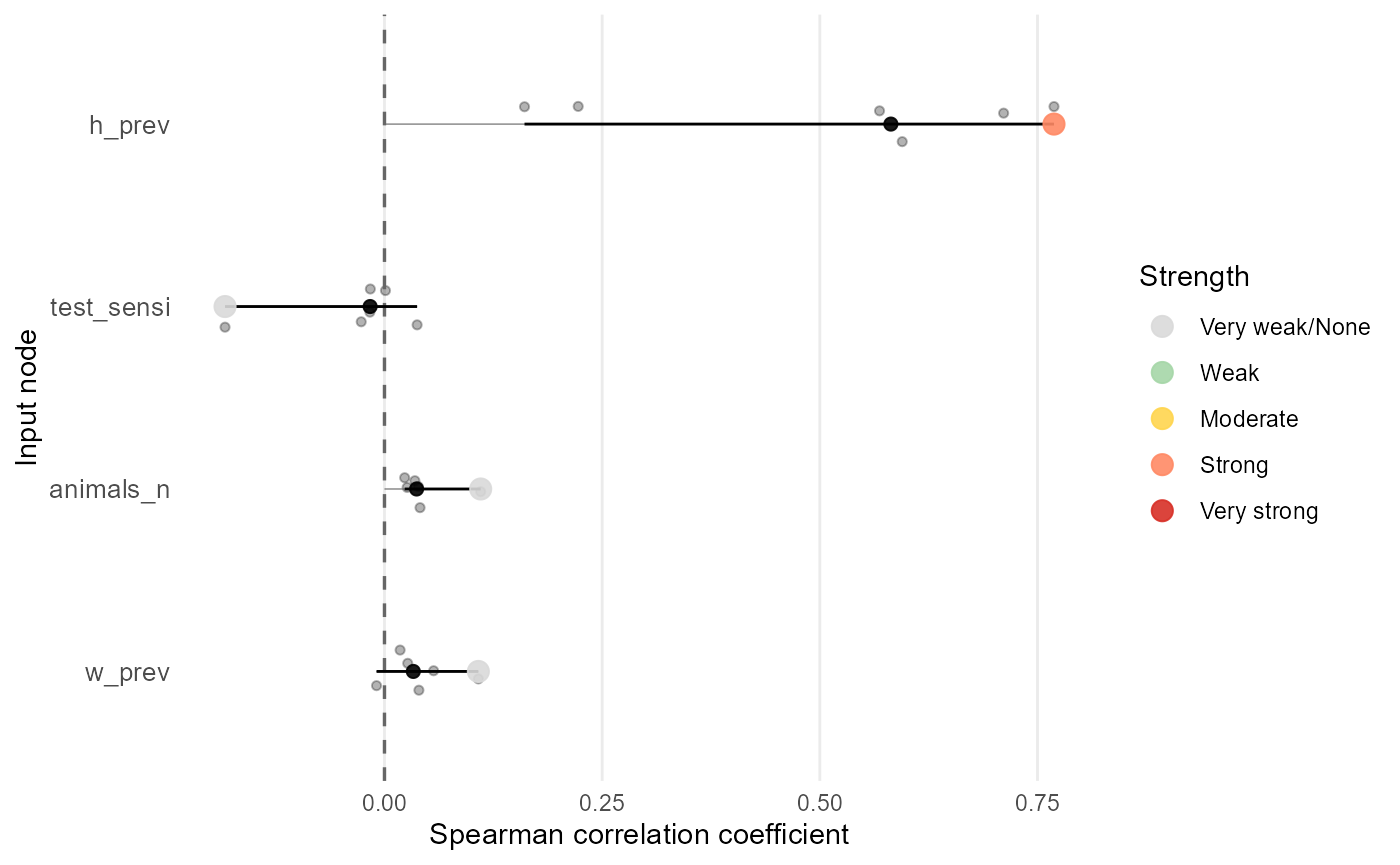
Sensitivity analysis
Sensitivity analysis quantifies how changes in inputs affect model
outputs, helping to identify which uncertainties are most important for
decision-relevant results. In mcmodule, you can perform
sensitivity analysis using sample design-based methods such as Morris or
Sobol indices for global sensitivity analysis. Different methods using
sensitivity (Iooss et al. 2025) or
sensobol (Puy et al. 2022) R packages are
described in the Sensitivity analysis vignette.
Sobol indices analysis
Sobol analysis decomposes output variance into first-order and higher-order effects, providing a global sensitivity analysis. It identifies which inputs contribute most to output uncertainty and whether interactions between inputs are important.
To perform Sobol analysis, first generate sampling matrices from your
mctable definitions, then evaluate the module with these
sample designs, and finally compute the indices:
library(sensobol)
#> Warning: package 'sensobol' was built under R version 4.5.2
# Generate Sobol sampling matrices from mctable
N <- 1000 # Number of base samples
X <- mctable_sobol_matrices(imports_mctable, N = N)
# Evaluate the module with the Sobol sample design
imports_sobol <- eval_module(
exp = c(imports = imports_exp),
data = NULL,
sample_design = X,
mctable = imports_mctable
)
#> imports evaluated
#> mcmodule created (expressions: imports)
# Calculate the target output
imports_sobol <- trial_totals(
mcmodule = imports_sobol,
mc_names = c("no_detect"),
trials_n = "animals_n",
subsets_n = "farms_n",
subsets_p = "h_prev",
sample_design = X,
mctable = imports_mctable
)
# Extract output and compute Sobol indices
y <- unmc(imports_sobol$node_list$no_detect_set_n$mcnode)
sobol_sa <- sensobol::sobol_indices(Y = y, N = N, params = colnames(X))
# View and plot results
print(sobol_sa)
#>
#> First-order estimator: saltelli | Total-order estimator: jansen
#>
#> Total number of model runs: 8000
#>
#> Sum of first order indices: 0.7875086
#> original sensitivity parameters
#> <num> <char> <char>
#> 1: 0.3277748245 Si h_prev
#> 2: 0.1382772638 Si w_prev
#> 3: 0.0005761916 Si test_sensi
#> 4: 0.0474118399 Si farms_n
#> 5: 0.0453604440 Si animals_n
#> 6: 0.2281079995 Si test_origin
#> 7: 0.4860749024 Ti h_prev
#> 8: 0.2316100375 Ti w_prev
#> 9: 0.0007907512 Ti test_sensi
#> 10: 0.0744399057 Ti farms_n
#> 11: 0.0904267518 Ti animals_n
#> 12: 0.3402352428 Ti test_origin
plot(sobol_sa)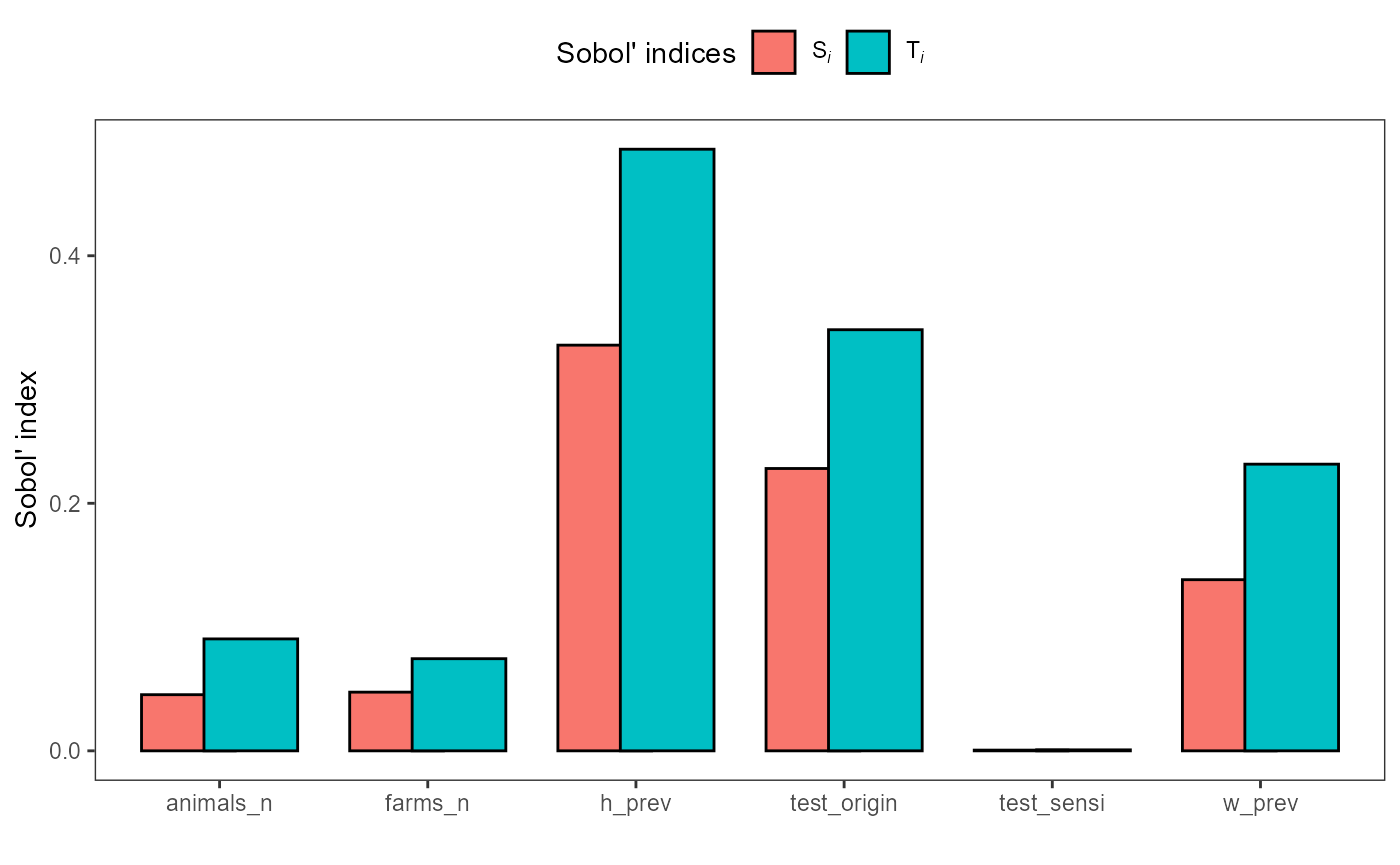
The first-order index (Si) quantifies each input’s
direct contribution to output variance, while the total-order index
(Ti) captures total contribution including interactions.
Inputs with large Si values are important drivers of output
uncertainty and should be prioritized for data collection and
uncertainty reduction.
Tricks and tweaks
Handling missing and infinite values in mcnodes
When building stochastic nodes, you may encounter missing
(NA) or infinite (Inf, -Inf)
values, especially after mathematical operations or data
transformations. These can cause issues in downstream calculations. Use
mcnode_na_rm() to clean your mcnode by replacing
problematic values with another value (usually zero):
sample_mcnode <- mcstoc(runif,
min = mcdata(c(NA, 0.2, -Inf), type = "0", nvariates = 3),
max = mcdata(c(NA, 0.3, Inf), type = "0", nvariates = 3),
nvariates = 3
)
#> Warning in (function (n, min = 0, max = 1) : NAs produced
#> Warning in (function (n, min = 0, max = 1) : NAs produced
# Replace NA and Inf with 0
clean_mcnode <- mcnode_na_rm(sample_mcnode)This is especially useful in expressions where a denominator might be
zero, resulting in Inf or NaN, but you want
the output to be zero instead.
A similar function is mcnode_null_rm(), that allows you
replace missing nodes, required a in expression but not found in the
input data with an value (usually zero).
Customizing total node names
Functions like at_least_one(),
agg_totals(), and trial_totals() automatically
generate new mcnodes with informative suffixes. You can customize these
names for clarity or documentation purposes:
# Custom name for at_least_one()
intro <- at_least_one(intro, c("no_detect", "dir_contact"), name = "custom_total")
#> 2 variates per group for dir_contact
#> 2 variates per group for dir_contact
#> 2 variates per group for dir_contact
#> 2 variates per group for dir_contact
#> no_detect prev dim: [1001, 1, 12], new dim: [1001, 1, 24], 0 null matches
#> dir_contact prev dim: [1001, 1, 12], new dim: [1001, 1, 24], 0 null matches
# Custom name for agg_totals()
intro <- agg_totals(intro, "no_detect_set", name = "custom_agg")
#> Keys to aggregate by not provided, using 'scenario_id' by default
#> 6 variates per group for no_detect_set
# Custom suffix for agg_totals()
intro <- agg_totals(intro, "no_detect_set",
agg_keys = c("scenario_id", "pathogen"),
agg_suffix = "aggregated"
)
#> 3 variates per group for no_detect_setPrefixing mcmodules to avoid name duplication
If your project includes multiple modules with similar or repeated
expressions, duplicated node names can cause problems when combining
modules. Use add_prefix() to add a unique prefix to each
module, making node names distinct:
imports_wif <- add_prefix(imports_wif)By default, the prefix is the mcmodule name, but you can specify a custom prefix if needed.
Functions that work outside mcmodules
Some functions in mcmodule can be used independently of
the full module workflow:
-
create_mcnodes(): Quickly generate mcnodes from a data frame and mctable, useful for prototyping or testing
create_mcnodes(data = prevalence_region, mctable = imports_mctable)
# Nodes are created in the environment
h_prev
#> node mode nsv nsu nva variate min mean median max Nas type outm
#> 1 x numeric 1001 1 6 1 0.08 0.0900 0.0901 0.10 0 V each
#> 2 x numeric 1001 1 6 2 0.02 0.0353 0.0354 0.05 0 V each
#> 3 x numeric 1001 1 6 3 0.10 0.1254 0.1258 0.15 0 V each
#> 4 x numeric 1001 1 6 4 0.50 0.6034 0.6049 0.70 0 V each
#> 5 x numeric 1001 1 6 5 0.25 0.2751 0.2755 0.30 0 V each
#> 6 x numeric 1001 1 6 6 0.30 0.4001 0.4000 0.50 0 V each-
mc_summary(): Summarize a mcnode directly from data, without needing a full mcmodule
mc_summary(data = prevalence_region, mcnode = h_prev, keys_names = c("pathogen", "origin"))
#> mc_name pathogen origin mean sd Min 2.5%
#> 1 h_prev a nord 0.09001996 0.005891111 0.08003034 0.08034608
#> 2 h_prev a south 0.03529671 0.008760181 0.02000377 0.02070467
#> 3 h_prev a east 0.12544979 0.014760990 0.10002194 0.10116112
#> 4 h_prev b nord 0.60342558 0.058223251 0.50003834 0.50540040
#> 5 h_prev b south 0.27506704 0.014794917 0.25001090 0.25151509
#> 6 h_prev b east 0.40012251 0.058103232 0.30000118 0.30554457
#> 25% 50% 75% 97.5% Max nsv Na's
#> 1 0.08485688 0.09010935 0.09520160 0.09951931 0.09999556 1001 0
#> 2 0.02801205 0.03540434 0.04297248 0.04915296 0.04997527 1001 0
#> 3 0.11171139 0.12579266 0.13856562 0.14895085 0.14987947 1001 0
#> 4 0.55229871 0.60494464 0.65392433 0.69547649 0.69993449 1001 0
#> 5 0.26219757 0.27549083 0.28823216 0.29907877 0.29996905 1001 0
#> 6 0.34956681 0.39999951 0.44839734 0.49640704 0.49978359 1001 0Convert to other formats
You can transform a full mcmodule into a list of matrices or of
mc2d mc objects with
mcmodule_to_matrices() and mcmodule_to_mc()
respectively.
Next steps
We are currently planning to add global sensitivity
analysis based on Morris screening, using the existing local
sensitivity (OAT) support (see eval_module()).
We are also working on building compatibility with other R packages
such as freedom, to facilitate integration with broader
risk assessment workflows.
To stay updated on new releases and planned features, watch our repository: https://github.com/NataliaCiria/mcmodule. We encourage you to explore the package further, adapt it to your own use cases, and contribute feedback or improvements. To report bugs, please visit: https://github.com/NataliaCiria/mcmodule/issues or contact mail@nataliaciria.com.